ISIS 3 Application Documentation
findfeatures | Printer Friendly View | TOC | Home |
Feature-based matching algorithms used to create ISIS control networks
| Overview | Parameters | Example 1 | Example 2 |
DescriptionIntroductionfindfeatures was developed to provide an alternative approach to create image-based ISIS control point networks. Traditional ISIS control networks are typically created using equally spaced grids and area-based image matching (ABM) techniques. Control points are at the center of these grids and they are not necessarily associated with any particular feature or interest point. findfeatures applies feature-based matching (FBM) algorihms using the full suite of OpenCV detection and descriptor extraction algorithms and descriptor matchers. The points detected by these algorithms are associated with special surface features identified by the type of detector algorithm designed to identify certain charcteristics. Feature based matching has a twenty year history in computer vision and continues to benefit from improvements and advancements to make development of applications like this possible. This application offers alternatives to traditional image matching options such as autoseed, seedgrid and coreg. Applications like coreg and pointreg are area-based matching, findfeatures utilizes feature-based matching techniques. The OpenCV feature matching framework is used extensively in this application to implement the concepts contained in a robust feature matching algorithm applied to overlapping single pairs or multiple overlapping image sets. Overviewfindfeatures uses OpenCV 3.1's FBM algorithms to match a single image, or set of images, called the trainer image(s) to a different image, called the query image. Feature based algorithms are comprised of three basic processes: detection of features (or keypoints), extraction of feature descriptors and finally matching of feature descriptors from two image sources. To improve the quality of matches, findfeatures applies a fourth process, robust outlier detection. Feature detection is the search for features of interest (or key points) in an image. The ultimate goal is to find features that can also be found in another image of the same subject or location. Feature detection algorithms are often refered to as detectors. Detectors describe key points based on their location in a specific image. Feature descriptors allow features found by a detector to be described outside of the context of that image. For example, features could be described by their roundness or how much they contrast the surrounding area. Feature descriptors provide a way to compare key points from different images. Algorithms that extract feature descriptors from keypoints in an image are called extractors. The third process is to match key points from different images based on their feature descriptors. The trainer images can be matched to the query image (called a trainer to query match) or the query image can be matched to the trainer images (called a query to trainer match). findfeatures performs both a trainer to query match and a query to trainer match. Algorithms for matching feature descriptors are called matchers. The final step is to remove outlier matches. This helps improve the quality and accuracy of matches when conditions make matching challenging. findfeatures uses a four step outlier removal process. At each step, matches are rejected and only the surviving matches are used in the following step.
Matches that survive the outlier rejection process are converted into an output control network. From here, multiple control networks created by systematic use of findfeatures can be combined into one regional or global control network with cnetcombinept. This can result in extremely large control networks. cnetthinner can be used to reduce the size of the network while maintaining sufficient distribution for use with the jigsaw application. If the control network is going to be used to create a DEM, then it should not be thinned. Supported Image Formatsfindfeatures is designed to support many different image formats. However, ISIS cubes with camera models provide the greatest flexibility when using this feature matcher. ISIS cubes with geometry can be effectively and efficiently matched by applying fast geometric transforms that project all overlapping candidate images (referred to as train images in OpenCV terminolgy) to the camera space of the match (or truth) image (referred to as the query image in OpenCV terminology). This single feature allows users to apply virtually all OpenCV detector and extractor, including algorithms that are not scale and rotation invariant. Other popular image formats are supported using OpenCV imread() image reader API. Images supported here can be provided as the image input files. However, these images will not have geometric functionality so support for the fast geometric option is not available to these images. As a consequence, FBM algorithms that are not scale and rotation invarant are not recommended for these images unless they are relatively spatially consistent. Nor can the point geometries be provided - only line/sample coorelations will be computed in these cases. Note that all images are converted to 8-bit when read in. Specifying Algorithms and Robust Matcher Parameters
Detectors, extractors, matchers, and robust matcher parameters are
specified by a specification string entered as the ALGORITHM
parameter. The basic scheme is shown below (optional portions are
surrounded by
detector[@param1:value1@...]/extractor[@param1:value@...][/matcher@param1@value1@...][/parameters@param1:value1@...]
The specification string consists of between two and four components
separated by
An alternative scheme for the specification string allows the
components to be in any order. Each component is formatted the same,
except the first entry in the detector, extractor, and (if specified)
matcher components begin with
extractor.LATCH@Bytes:16@HalfSSDSize:4/parameters@RootSift:true/matcher.FlannBasedMatcher/detector.FAST@Threshold:9@NonmaxSuppression:false
Many FBM algorithms are designed to use a specific detector, extractor
pair with shared parameters (SIFT and SURF are good examples of this).
For these cases, the alternative specification scheme allows for the
detector and extractor to be defined in a single component with shared
parameters. To do this, begin the first entry with
matcher.BFMatcher@NormType:Norm_L1/feature2d.SIFT@NOctaveLayers:4.
The minimum specification string consists of a detector name and an
extractor name. When no matcher is specified, a brute force matcher
with parameters tailored to the extractor is used. For example
Multiple sets of FBM algorithms and robust matcher parameters can be entered via the ALGOSPECFILE parameter. It takes a text file (*.lis) with a specification on each line. For each specification, a separate set of FBM algorithms and robust matcher parameters will be created. Each set will be used to match the input images and the set that produces the best matches will be used to create the output control network. When the DEBUG and/or DEBUGLOG parameters are used, the results from each set along with the quality of the match will be output. Each algorithm has default parameters that are suited to most uses. The LISTALL parameter will list every supported detector, extractor, and matcher algorithm along with its parameters and default values. The LISTSPEC parameter will output the results of the parsed specification string(s). A description of every algorithm supported by findfeatures and if they can be used as a detector, extractor, and/or matcher can be found in the Algorithms table. Descriptions of the robust matcher parameters and their default values can be found in the Robust Matcher Parameters table. Choosing Algorithms and ParametersChoosing effective algorithms and parameters is critical to successful use of findfeatures. If a poor choice of algorithms and/or parameters is made, findfeatures will usually complete, but the computation time and/or output control network quality will suffer. findfeatures supports all of the OpenCV 3.1 detectors, extractors, and matchers. Some algorithms work well in a wide range of scenarios (SURF and SIFT are both well tested and very robust), while others are highly specialized. The following section will help you successfully determine which algorithms and parameters to use. findfeatures gives users a wide range of options to adjust how it works. Such broad power can be daunting when the user is unfamiliar with FBM. The following are some rules-of-thumb to help make things a little less daunting. First, when in doubt, trust the defaults. The defaults in findfeatures are designed to be a good fit for a wide range of scenarios. They are not a perfect fit for every situation but a perfect fit usually is not required. The detector and extractor do not default to a specific algorithm, but the SIFT algorithm is a very robust algorithm that will produce a high quality output control network for most situations. The majority of more modern algorithms are focused on speed increases. Second, if possible, always use the FASTGEOM parameter. The majority of problems when using FBM arise from the trainer and query images not having the same geometry. The FASTGEOM parameter completely eliminates these challenges. Combining the FASTGEOM parameter with algorithms that are designed for speed (the FAST descriptor and BRIEF extractor are good options) will quickly produce a high quality control network. Finally, if you are torn between a few options, use the LISTSPEC parameter to test each of them and then only use the best result. When the LISTSPEC parameter is used, findfeatures will automatically determine which specification produced the best matches and use it to create the output control net. Different detectors search for different types of features. For example, the FAST algorithm searches for corners, while blob detection algorithms search for regions that contrast their surroundings. When choosing which detector to use, consider the prominent features in the image set. The FAST algorithm would work well for finding key points on a linear feature, while a blob detection algorithm would work well for finding key points in nadir images of a heavily cratered area. When choosing an extractor there are two things to consider: the invariance of the extractor and the size of the extracted descriptor. Different extractors are invariant to (not affected by) different transformations. For example, the SURF algorithm uses descriptors that are invariant to rotation, while BRIEF feature descriptors are not. In general, invariance to more transformations comes at a cost, bigger descriptors. Detectors often find a very large number of key points in each image. The amount of time it takes to extract and then compare all of the resultant feature descriptors heavily depends upon the size of the descriptor. So, more invariance usually means longer computation times. For example, using the BRIEF extractor (which extracts very small feature descriptors) instead of the SURF extractor (which has moderately sized feature descriptors) provides an order of magnitude speed increases for both extraction and matching. If your images are from the similar sensors and under similar conditions, then an extractor that uses smaller descriptors (BRISK, BRIEF, etc.) will be faster and just as accurate as extractors that use larger, more robust descriptors (SIFT, SURF, etc.). If your images are from very different sensors (a spot spectrometer and a highly distorted framing camera, a low resolution framing camera and a high resolution push broom camera, etc.) or under very different conditions (very oblique and nadir, opposing sun angles, etc.) then using an extractor with a more robust descriptor will take longer but will be significantly more accurate than using an extractor with a smaller descriptor. findfeatures has two options for matchers: brute force matching and a FLANN based matcher. The brute force matcher attempts to match a key point with every key point in another image and then pairs it with the closest match. This ensures a good match but can take a long time for large numbers of images and key points. The FLANN based matcher trains itself to find the approximate best match. It does not ensure the same accuracy as the brute force matcher, but is significantly faster for large numbers of images and key points. By default findfeatures uses a brute force matcher with parameters set based upon the extractor used. Several parameters allow for fine tuning the outlier rejection process. The RATIO parameter determines how distinct matches must be. A ratio close to 0 will force findfeatures to consider only un-ambiguous matches and reject a large number of matches. If many, indistinct features are detected in each image, a low ratio will result in a smaller, higher quality control network. If few, non-distinct features are detected in each image, a high ratio will prevent the control network from being too sparse. The EPITOLERANCE and EPICONFIDENCE parameters control how outliers are found when the fundamental matrices are computed. These parameters will have the highest impact when the query and trainer images are stereo pairs. The HMGTOLERANCE parameter controls how outliers are found after the homography matrices are computed. This parameter will have the highest impact when the query and trainer images have very different exterior orientations. Prior to FBM, findfeatures can apply several transformations to the images. These transformations can help improve match quality in specific scenarios. The FASTGEOM, GEOMTYPE, and FASTGEOMPOINTS parameters allow for reprojection of the trainer images into the query image's geometry prior to FBM. These parameters can be used to achieve the speed increases of algorithms that are not rotation and/or scale invariant (BRIEF, FAST, etc.) without loss of accuracy. These parameters require that the trainer and query images are ISIS cubes with geometry. For rotation and scale invariant algorithms (SIFT, SURF, etc.), these parameters will have little to no effect. The FILTER parameter allows for the application of filters to the trainer and query images prior to FBM. The SOBEL option will emphasize edges in the images. The Sobel filter can introduce artifacts into some images, so the SCHARR option is available to apply a more accurate filter. These filters allows for improved detection when using an edge based detector (FAST, AGAST, BRISK, etc.). If an edge based detector is not detecting a sufficient number of key points or the key points are not sufficienty distinct, these filters may increase the number of successful matches. The OpenCV methods used in the outlier rejection process have several options that can be set along with the algorithms. The available parameters are listed in the Robust Matcher Parameters table.
Using Debugging to Diagnose BehaviorAn additional feature of findfeatures is a detailed debugging report of processing behavior in real time for all matching and outlier detection algorithms. The data produced by this option is very useful to identify the exact processing step where some matching operations may result in failed matching operations. In turn, this will allow users to alter parameters to address these issues to lead to successful matches that would otherwise not be able to achieve. To invoke this option, users set DEBUG=TRUE and provide an optional output file (DEBUGLOG=filename) where the debug data is written. If no file is specified, output defaults to the terminal device. Here is an example (see the example section for details) of a debug session with line numbers added for reference of the description that follows:
1 ---------------------------------------------------
2 Program: findfeatures
3 Version 0.1
4 Revision: $Revision: 7311 $
5 RunTime: 2017-01-03T16:59:01
6 OpenCV_Version: 3.1.0
7
8 System Environment...
9 Number available CPUs: 4
10 Number default threads: 4
11 Total threads: 4
12
13 Total Algorithms to Run: 1
14
15 @@ matcher-pair started on 2017-01-03T16:59:02
16
17 +++++++++++++++++++++++++++++
18 Entered RobustMatcher::match(MatchImage &query, MatchImage &trainer)...
19 Specification: surf@hessianThreshold:100/surf/BFMatcher@NormType:NORM_L2@CrossCheck:false
20 ** Query Image: EW0211981114G.lev1.cub
21 FullSize: (1024, 1024)
22 Rendered: (1024, 1024)
23 ** Train Image: EW0242463603G.lev1.cub
24 FullSize: (1024, 1024)
25 Rendered: (1024, 1024)
26 --> Feature detection...
27 Total Query keypoints: 11823 [11823]
28 Total Trainer keypoints: 11989 [11989]
29 Processing Time: 0.307
30 Processing Keypoints/Sec: 77563.5
31 --> Extracting descriptors...
32 Processing Time(s): 0.9
33 Processing Descriptors/Sec: 26457.8
34
35 *Removing outliers from image pairs
36 Entered RobustMatcher::removeOutliers(Mat &query, vector<Mat> &trainer)...
37 --> Matching 2 nearest neighbors for ratio tests..
38 Query, Train Descriptors: 11823, 11989
39 Computing query->train Matches...
40 Total Matches Found: 11823
41 Processing Time: 1.906
42 Matches/second: 6203.04
43 Computing train->query Matches...
44 Total Matches Found: 11989
45 Processing Time: 2.412 <seconds>
46 Matches/second: 4970.56
47 -Ratio test on query->train matches...
48 Entered RobustMatcher::ratioTest(matches[2]) for 2 NearestNeighbors (NN)...
49 RobustMatcher::Ratio: 0.65
50 Total Input Matches Tested: 11823
51 Total Passing Ratio Tests: 988
52 Total Matches Removed: 10835
53 Total Failing NN Test: 10835
54 Processing Time: 0
55 -Ratio test on train->query matches...
56 Entered RobustMatcher::ratioTest(matches[2]) for 2 NearestNeighbors (NN)...
57 RobustMatcher::Ratio: 0.65
58 Total Input Matches Tested: 11989
59 Total Passing Ratio Tests: 1059
60 Total Matches Removed: 10930
61 Total Failing NN Test: 10930
62 Processing Time: 0
63 Entered RobustMatcher::symmetryTest(matches1,matches2,symMatches)...
64 -Running Symmetric Match tests...
65 Total Input Matches1x2 Tested: 988 x 1059
66 Total Passing Symmetric Test: 669
67 Processing Time: 0.012
68 Entered RobustMatcher::computeHomography(keypoints1/2, matches...)...
69 -Running RANSAC Constraints/Homography Matrix...
70 RobustMatcher::HmgTolerance: 1
71 Number Initial Matches: 669
72 Total 1st Inliers Remaining: 273
73 Total 2nd Inliers Remaining: 266
74 Processing Time: 0.041
75 Entered EpiPolar RobustMatcher::ransacTest(matches, keypoints1/2...)...
76 -Running EpiPolar Constraints/Fundamental Matrix...
77 RobustMatcher::EpiTolerance: 1
78 RobustMatcher::EpiConfidence: 0.99
79 Number Initial Matches: 266
80 Inliers on 1st Epipolar: 219
81 Inliers on 2nd Epipolar: 209
82 Total Passing Epipolar: 209
83 Processing Time: 0.01
84 Entered RobustMatcher::computeHomography(keypoints1/2, matches...)...
85 -Running RANSAC Constraints/Homography Matrix...
86 RobustMatcher::HmgTolerance: 1
87 Number Initial Matches: 209
88 Total 1st Inliers Remaining: 197
89 Total 2nd Inliers Remaining: 197
90 Processing Time: 0.001
91 %% match-pair complete in 5.589 seconds!
In the above example, lines 2-13 provide general information about the program and compute environment. If MAXTHREADS were set to a value less than 4, number of total threads (line 11) would reflect this number. Line 15 specifies the precise time the matcher algorithm was invoked. Line 18-25 shows the algorithm string specification, names of query (MATCH) and train (FROM) images and the full and rendered sizes of images. Lines 27 and 28 show the total number of keypoints or features that were detected by the SURF detector for both the query (11823) and train (11989) images. Lines 31-33 indicate the descriptors of all the feature keypoints are being extracted. Extraction of keypoint descriptors can be costly under some conditions. Users can restrict the number of features detected by using the MAXPOINTS parameter specify the maximum numnber of points to save. The values in brackets in lines 27 and 28 will show the total amount of features detected if MAXPOINTS are used. Outlier detection begins at line 35. The Ratio test is performed first. Here the matcher algorithm is invoked for each match pair, regardless of the number of train (FROMLIST) images provided. For each keypoint in the query image, the two nearest matches in the train image are computed and the results are reported in lines 39-42. Then the bi-directional matches are computed in lines 43-46. A bi-directional ratio test is computed for the query->train matches in lines 47-54 and then train->query in lines 55-62. You can see here that a significant number of matches are removed in this step. Users can adjust this behavior, retaining more points by setting the RATIO parameter closer to 1.0. The symmetry test, ensuring matches from query->train have the same match as train->query, is reported in lines 63-67. In lines 68-74, the homography matrix is computed and outliers are removed where the tolerance exceeds HMGTOLERANCE. Lines 75-83 shows the results of the epipolar fundamental matrix computation and outlier detection. Matching is completed in lines 84-90 which report the final spatial homography computations to produce the final transformation matrix between the query and train images. Line 89 shows the final number of control measures computed between the image pairs. Lines 35-90 are repeated for each query/train image pair (with perhaps slight formatting differences). Line 91 shows the total processing time for the matching process. Evaluation of Matcher Algorithm Performancefindfeatures provides users with many features and options to create unique algorithms that are suitable for many of the diverse image matching conditions that naturally occur during a spacecraft mission. Some are more suited for certain conditions that others. But how does one determine which algorithm combination performs the best for an image pair? By computing standard performance metrics, one can make a determination as to which algorithm performs best. Using the ALGOSPECFILE parameter, users can specify one or more algorithms to apply to a given image matching process. Each algorithm specified, one per line in the input file, results in a the creation of a unique robust matcher algorithm thatis applied to the input files in succession. The performance of each algorithm is computed for each of the matcher from a standard set of metrics described in a thesis titled Efficient matching of robust features for embedded SLAM. From the metrics described in this paper, a single metric that measures the abilities of the whole matching process is computed that are relevant to all three FBM steps: detection, description and matching. This metric is called Efficiency. The Efficiency metric is computed from two other metrics called Repeatability and Recall.
Repeatability represents the ability to detect the same point
in the scene under viewpoint and lighting changes and subject to
noise. The value of Repeatability is calculated as:
Recall represents the ability to find the correct
matches based on the description of detected features, The value of
Recall is calculated as:
Efficiency combines the Repeatability and
Recall. It is defined as:
findfeatures computes the Efficiency for each algorithm and selects the matcher algorithm combination with the highest value. This value is reported at the end of the run of application in the MatchSolution group. Here is an example:
Group = MatchSolution
Matcher = surf@hessianThreshold:100/surf/BFMatcher@NormType:NORM_L2@CrossCheck:false
MatchedPairs = 1
Efficiency = 0.040744395883265
End_Group
CategoriesHistory
|
Parameter GroupsFiles
Algorithms
Constraints
Image Transformation Options
Control
|
Files: FROM
Description
This cube/image (train) will be translated to register to the MATCH (query) cube/image. This application supports other common image formats such as PNG, TIFF or JPEG. Essentially any image that can be read by OpenCV's imread()routine is supported. All input images are converted to 8-bit when they are read.
| Type | cube |
|---|---|
| File Mode | input |
| Default | None |
| Filter | *.cub |
Files: FROMLIST
Description
Use this parameter to select a filename which contains a list of cube filenames. The cubes identified inside this file will be used to create the control network. All input images are converted to 8-bit when they are read. The following is an example of the contents of a typical FROMLIST file:
AS15-M-0582_16b.cub
AS15-M-0583_16b.cub
AS15-M-0584_16b.cub
AS15-M-0585_16b.cub
AS15-M-0586_16b.cub
AS15-M-0587_16b.cub
Each file name in a FROMLIST file should be on a separate line.
| Type | filename |
|---|---|
| File Mode | input |
| Internal Default | None |
| Filter | *.lis |
Files: MATCH
Description
Name of the image to match to. This will be the reference image in the output control network. It is also referred to as the query image in OpenCV documentation. All input images are converted to 8-bit when they are read.
| Type | cube |
|---|---|
| File Mode | input |
| Default | None |
| Filter | *.cub |
Files: ONET
Description
This file will contain the Control Point network results of findfeatures in a binary format. There will be no false or failed matches in the output control network file. Using this control network and TOLIST in the qnet application, the results of findfeatures can be visually assessed.
| Type | filename |
|---|---|
| File Mode | output |
| Internal Default | None |
| Filter | *.net *.txt |
Files: TOLIST
Description
This file will contain the list of (cube) files in the control network. For multi-image matching, some files may not have matches detected. These files will not be written to TOLIST. The MATCH file is always added first and all other images that have matches are added to TOLIST. Using this list and the ONET in the qnet application, the results of findfeatures can be visually assessed.
| Type | filename |
|---|---|
| File Mode | output |
| Internal Default | None |
| Filter | *.lis |
Files: TONOTMATCHED
Description
This file will contain the list of (cube) files that were not successfully matched. This can be used to run through individually with more specifically tailored matcher algorithm specifications.
NOTE this file is appended to so that continual runs will accumulate failures making it easier to handle failed runs.
| Type | filename |
|---|---|
| File Mode | output |
| Internal Default | None |
| Filter | *.lis |
Algorithms: ALGORITHM
Description
This parameter provides user control over selecting a wide variety of feature detectors, extractors and matcher combinations. This parameter also provides a mechanism to set any of the valid parameters of the algoritms.
| Type | string |
|---|---|
| Internal Default | None |
Algorithms: ALGOSPECFILE
Description
To accomodate a potentially large set of feature algorithms, you can provide them in a file. This format is the same as the ALGORITHM format, but each unique algorithm must be specifed on a seperate line. Thoeretically, the number you specify is unlimited. This option is particularly useful to generate a series of algorithms that vary parameters for any of the elements of the feature algorithm.
| Type | filename |
|---|---|
| Internal Default | None |
| Filter | *.lis |
Algorithms: LISTSPEC
Description
If true, information about the detector, extractor, matcher, and parameters specified in the ALGORITHM or ALGOSPECFILE parameters will be output. If multiple sets of algorithms are specified, then the details for each set will be output.
| Type | boolean |
|---|---|
| Default | No |
Algorithms: LISTALL
Description
This parameter will retrieve all the registered OpenCV algorithms available that can created by name.
| Type | boolean |
|---|---|
| Default | No |
Algorithms: TOINFO
Description
When an information option is requested (LISTSPEC), the user can provide the name of an output file here where the information, in the form of a PVL structure, will be written. If any of those options are selected by the user, and a file is not provided in this option, the output is written to the screen or GUI.
One very nifty option that works well is to specify the
terminal device as the output file. This will list the
results to the screen so that your input can be quickly
checked for accuracy. Here is an example using the algorithm
listing option and the result:
findfeatures listspec=true
algorithm=detector.Blob@minrepeatability:1/orb
toinfo=/dev/tty
Object = FeatureAlgorithms
Object = RobustMatcher
OpenCVVersion = 3.1.0
Name = detector.Blob@minrepeatability:1/orb/BFMatcher@NormType:N-
ORM_HAMMING@CrossCheck:false
Object = Detector
CVVersion = 3.1.0
Name = Blob
Type = Feature2D
Features = Detector
Description = "The OpenCV simple blob detection algorithm. See the
documentation at
http://docs.opencv.org/3.1.0/d0/d7a/classcv_1_1SimpleBlo-
bDetector.html"
CreatedUsing = detector.Blob@minrepeatability:1
Group = Parameters
BlobColor = 0
FilterByArea = true
FilterByCircularity = false
FilterByColor = true
FilterByConvexity = true
FilterByInertia = true
MaxArea = 5000
maxCircularity = inf
MaxConvexity = inf
MaxInertiaRatio = inf
MaxThreshold = 220
MinArea = 25
MinCircularity = 0.8
MinConvexity = 0.95
MinDistance = 10
MinInertiaRatio = 0.1
minrepeatability = 1
MinThreshold = 50
ThresholdStep = 10
End_Group
End_Object
Object = Extractor
CVVersion = 3.1.0
Name = ORB
Type = Feature2D
Features = (Detector, Extractor)
Description = "The OpenCV ORB Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/db/d95/classcv_1_1ORB.html"
CreatedUsing = orb
Group = Parameters
edgeThreshold = 31
fastThreshold = 20
firstLevel = 0
nfeatures = 500
nlevels = 8
patchSize = 31
scaleFactor = 1.2000000476837
scoreType = HARRIS_SCORE
WTA_K = 2
End_Group
End_Object
Object = Matcher
CVVersion = 3.1.0
Name = BFMatcher
Type = DecriptorMatcher
Features = Matcher
Description = "The OpenCV BFMatcher DescriptorMatcher matcher
algorithm. See the documentation at
http://docs.opencv.org/3.1.0/d3/da1/classcv_1_1BFMatcher-
.html"
CreatedUsing = BFMatcher@NormType:NORM_HAMMING@CrossCheck:false
Group = Parameters
CrossCheck = No
NormType = NORM_HAMMING
End_Group
End_Object
Object = Parameters
EpiConfidence = 0.99
EpiTolerance = 3.0
FastGeom = false
FastGeomPoints = 25
Filter = None
GeomSource = MATCH
GeomType = CAMERA
HmgTolerance = 3.0
MaxPoints = 0
MinimumFundamentalPoints = 8
MinimumHomographyPoints = 8
Ratio = 0.65
RefineFundamentalMatrix = true
RootSift = false
SavePath = $PWD
SaveRenderedImages = false
End_Object
End_Object
End_Object
End
| Type | filename |
|---|---|
| Default | /dev/tty |
Algorithms: DEBUG
Description
At times, things go wrong. By setting DEBUG=TRUE, information is printed as elements of the matching algorithm are executed. This option is very helpful to monitor the entire matching and outlier detection processing to determine where adjustments in the parameters can be made to produce better results.
| Type | boolean |
|---|---|
| Default | false |
Algorithms: DEBUGLOG
Description
Provide a file that will have all the debugging content appended as it is generated in the processing steps. This file can be very useful to determine, for example, where in the matching and or outlier detection most of the matches are being rejected. The output can be lengthy and detailed, but is critical in the determination where adjustments to the parameters can be made to provide better results.
| Type | filename |
|---|---|
| Internal Default | None |
| Filter | *.log |
Algorithms: PARAMETERS
Description
This file can contain specialized parameters that will modify certain behaviors in the robust matcher algorithm. They can vary over time and are documented in the application descriptions.
| Type | filename |
|---|---|
| Internal Default | None |
| Filter | *.conf |
Algorithms: MAXPOINTS
Description
Specifies the maximum number of keypoints to save in the detection phase. If a value is not provided for this parameter, there will be no restriction set on the number of keypoints that will be used to match. If specified, then approximately MAXPOINTS keypoints with the highest/best detector response values are retained and passed on to the extractor and matcher algorithms. This parameter is useful for detectors that produce a high number of features. A large number of features will cause the matching phase and outlier detection to become costly and inefficient.
| Type | integer |
|---|---|
| Default | 0 |
Constraints: RATIO
Description
For each feature point, we have two candidate matches in the other image. These are the two best ones based on the distance between their descriptors. If this measured distance is very low for the best match, and much larger for the second best match, we can safely accept the first match as a good one since it is unambiguously the best choice. Reciprocally, if the two best matches are relatively close in distance, then there exists a possibility that we make an error if we select one or the other. In this case, we should reject both matches. Here, we perform this test by verifying that the ratio of the distance of the best match over the distance of the second best match is not greater than a given RATIO threshold. Most of the matches will be removed by this test. The farther from 1.0, the more matches will be rejected.
| Type | double |
|---|---|
| Default | 0.65 |
Constraints: EPITOLERANCE
Description
The tolerance specifies the maximum distance in pixels that feature may deviate from the Epipolar lines for each matching feature.
| Type | double |
|---|---|
| Default | 3.0 |
Constraints: EPICONFIDENCE
Description
This parameter indicates the confidence level of the epipolar determination ratio. A value of 1.0 requires that all pixels be valid in the epipolar computation.
| Type | double |
|---|---|
| Default | 0.99 |
Constraints: HMGTOLERANCE
Description
If we consider the special case where two views of a scene are separated by a pure rotation, then it can be observed that the fourth column of the extrinsic matrix will be made of all 0s (that is, translation is null). As a result, the projective relation in this special case becomes a 3x3 matrix. This matrix is called a homography and it implies that, under special circumstances (here, a pure rotation), the image of a point in one view is related to the image of the same point in another by a linear relation.
The parameter is used as a tolerance in the computation of the distance between keypoints using the homography matrix relationship between the MATCH image and each FROM/FROMLIST image. This will throw points out that are (dist > TOLERANCE * min_dist), the smallest distance between points.
| Type | double |
|---|---|
| Default | 3.0 |
Constraints: MAXTHREADS
Description
This parameter allows users to control the number of threads to use for image matching. A default is to use all available threads on system. If MAXTHREADS is specified, the maximum number of CPUs are used if it exceeds the number of CPUs physically available on the system or no more than MAXTHREADS will be used.
| Type | integer |
|---|---|
| Default | 0 |
Image Transformation Options: FASTGEOM
Description
When TRUE, this option will perform a fast geometric linear transformation that projects each FROM/FROMLIST image to the camera space of the MATCH image. Note this option theoretically is not needed for scale/rotation invariant feature matchers such as SIFT and SURF but there are limitations as to the invariance of these matchers. For matchers that are not scale and rotation invariant, this (or something like it) will be required to orient each images to similar spatial consistency. Users should determine the capabilities of the matchers used.
| Type | boolean |
|---|---|
| Default | false |
Image Transformation Options: GEOMTYPE
Description
Provide options as to how FASTGEOM projects data in the FROM (train) image to the MATCH (query) image space.
| Type | string | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Default | CAMERA | ||||||||||||
| Option List: |
|
Image Transformation Options: FILTER
Description
Apply an image filter to both images before matching. These filters are typically used in cases of low emission or incidence angles are present. They are intended to remove albedo and highlight edges and are well-suited for these types of feature detectors.
| Type | string | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Default | None | ||||||||||||
| Option List: |
|
Control: NETWORKID
Description
The ID or name of this particular control network. This string will be added to the output control network file, and can be used to identify the network.
| Type | string |
|---|---|
| Default | Features |
Control: POINTID
Description
This string will be used to create unique IDs for each control point created by this program. The string must contain a single series of question marks ("?"). For example: "VallesMarineris????"
The question marks will be replaced with a number beginning with zero and incremented by one each time a new control point is created. The example above would cause the first control point to have an ID of "VallesMarineris0000", the second ID would be "VallesMarineris0001" and so on. The maximum number of new control points for this example would be 10000 with the final ID being "VallesMarineris9999".
Note: Make sure there are enough "?"s for all the control points that might be created during this run. If all the possible point IDs are exhausted the program will exit with an error, and will not produce an output control network file. The number of control points created depends on the size and quantity of image overlaps and the density of control points as defined by the DEFFILE parameter.
Examples of POINTID:
- POINTID="JohnDoe?????"
- POINTID="Quad1_????"
- POINTID="JD_???_test1"
| Type | string |
|---|---|
| Default | FeatureId_????? |
Control: POINTINDEX
Description
This parameter can be used to specify the starting POINTID index number to assist in the creation of unique control point identifiers. Users must determine the highest used index and use the next number in the sequence to provide unique point ids.
| Type | integer |
|---|---|
| Default | 1 |
Control: DESCRIPTION
Description
A text description of the contents of the output control network. The text can contain anything the user wants. For example it could be used to describe the area of interest the control network is being made for.
| Type | string |
|---|---|
| Default | Find features in image pairs or list |
Control: NETTYPE
Description
There are two types of control network files that can be created in this application: IMAGE and GROUND. For IMAGE types, the pair is assumed to be overlapping pairs where control measures for both images are created. For NETTYPE=GROUND, only the FROM file measure is recorded for purposes of dead reckoning of the image using jigsaw.
| Type | string | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Default | IMAGE | |||||||||
| Option List: |
|
Control: GEOMSOURCE
Description
For input files that provide geometry, specify which one provides the latitude/longitude values for each control point. NONE is an acceptable option for which there is no geometry available. Otherwise, the user must choose FROM or MATCH as the cube file that wil provide geometry.
| Type | string | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Default | MATCH | ||||||||||||
| Option List: |
|
Control: TARGET
Description
This parameter is optional and not neccessary if using Level 1 ISIS cube files. It specifies the name of the target body that the input images are acquired of. If the input images are ISIS images, this value is retrieved from the camera model or map projection.
| Type | string |
|---|---|
| Internal Default | None |
Example 1Run matcher on pair of MESSENGER images Description
This example shows the results of matching two overlapping messenger
images of different scales. The following command was used to
produce the output network:
findfeatures algorithm="surf@hessianThreshold:100/surf" \
match=EW0211981114G.lev1.cub \
from=EW0242463603G.lev1.cub \
epitolerance=1.0 ratio=0.650 hmgtolerance=1.0 \
networkid="EW0211981114G_EW0242463603G" \
pointid="EW0211981114G_?????" \
onet=EW0211981114G.net \
description="Test MESSENGER pair" debug=true \
debuglog=EW0211981114G.log
Note that the fast geom option is not used for this example because
the SURF algorithm is scale and rotation invariant. Here is the
algorithm information for the specification of the matcher
parameters:
Object = FeatureAlgorithms
Object = RobustMatcher
OpenCVVersion = 3.1.0
Name = surf@hessianThreshold:100/surf/BFMatcher
Object = Detector
CVVersion = 3.1.0
Name = SURF
Type = Feature2D
Features = (Detector, Extractor)
Description = "The OpenCV SURF Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/d5/df7/classcv_1_1xfeatures-
2d_1_1SURF.html"
CreatedUsing = surf@hessianThreshold:100
Group = Parameters
Extended = No
hessianThreshold = 100
NOctaveLayers = 3
NOctaves = 4
Upright = No
End_Group
End_Object
Object = Extractor
CVVersion = 3.1.0
Name = SURF
Type = Feature2D
Features = (Detector, Extractor)
Description = "The OpenCV SURF Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/d5/df7/classcv_1_1xfeatures-
2d_1_1SURF.html"
CreatedUsing = surf
Group = Parameters
Extended = No
HessianThreshold = 100.0
NOctaveLayers = 3
NOctaves = 4
Upright = No
End_Group
End_Object
Object = Matcher
CVVersion = 3.1.0
Name = BFMatcher
Type = DecriptorMatcher
Features = Matcher
Description = "The OpenCV BFMatcher DescriptorMatcher matcher
algorithm. See the documentation at
http://docs.opencv.org/3.1.0/d3/da1/classcv_1_1BFMatcher-
.html"
CreatedUsing = BFMatcher
Group = Parameters
CrossCheck = No
NormType = NORM_L2
End_Group
End_Object
Object = Parameters
EpiConfidence = 0.99
EpiTolerance = 3.0
FastGeom = false
FastGeomPoints = 25
Filter = None
GeomSource = MATCH
GeomType = CAMERA
HmgTolerance = 3.0
MaxPoints = 0
MinimumFundamentalPoints = 8
MinimumHomographyPoints = 8
Ratio = 0.65
RefineFundamentalMatrix = true
RootSift = false
SavePath = $PWD
SaveRenderedImages = false
End_Object
End_Object
End_Object
End
The output debug log file and a line-by-line description of the result is shown in the main application documention. And here is the screen shot of qnet for the resulting network: 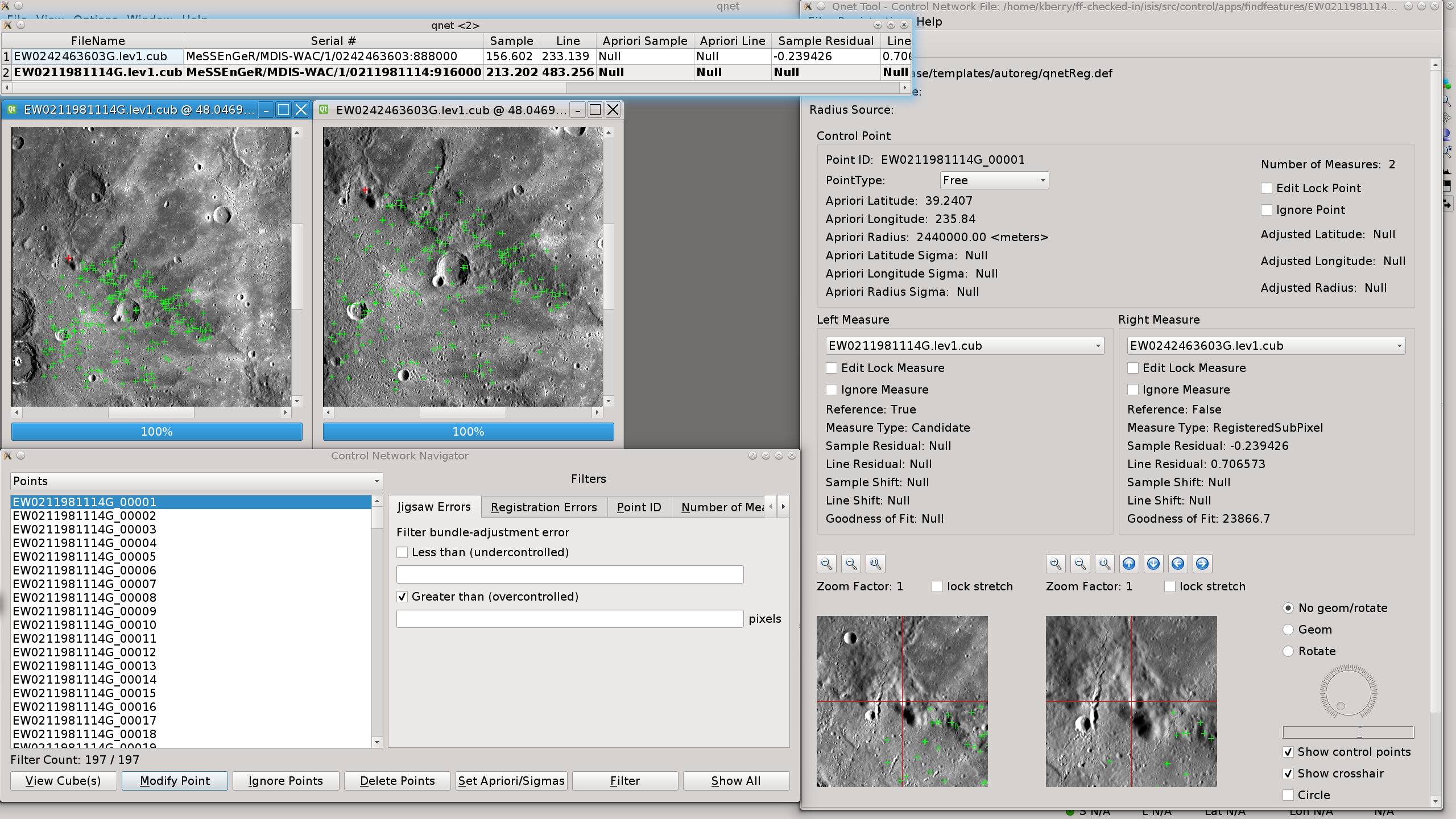
|
Example 2Show all the available algorithms and their default parameters Description
This provides a reference for all the current algorithms and their default parameters. This list may not include all the available OpenCV algorithms nor may all algorithms be applicable. Users should rerun this command to get the current options available on your system as they may differ.
findfeatures listall=yes
Object = Algorithms
Object = Algorithm
CVVersion = 3.1.0
Name = AGAST
Type = Feature2D
Features = Detector
Description = "The OpenCV AGAST Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/d7/d19/classcv_1_1AgastFeatur-
eDetector.html"
CreatedUsing = agast
Aliases = (agast, detector.agast)
Group = Parameters
NonmaxSuppression = Yes
Threshold = 10
Type = OAST_9_16
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = AKAZE
Type = Feature2D
Features = (Detector, Extractor)
Description = "The OpenCV AKAZE Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/d8/d30/classcv_1_1AKAZE.html"
CreatedUsing = akaze
Aliases = (akaze, detector.akaze, extractor.akaze, feature2d.akaze)
Group = Parameters
DescriptorChannels = 3
DescriptorSize = 0
DescriptorType = DESCRIPTOR_MLDB
Diffusivity = DIFF_PM_G2
NOctaveLayers = 4
NOctaves = 4
Threshold = 0.0010000000474975
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = Blob
Type = Feature2D
Features = Detector
Description = "The OpenCV simple blob detection algorithm. See the
documentation at
http://docs.opencv.org/3.1.0/d0/d7a/classcv_1_1SimpleBlobD-
etector.html"
CreatedUsing = blob
Aliases = (blob, detector.blob)
Group = Parameters
BlobColor = 0
FilterByArea = true
FilterByCircularity = false
FilterByColor = true
FilterByConvexity = true
FilterByInertia = true
MaxArea = 5000
maxCircularity = inf
MaxConvexity = inf
MaxInertiaRatio = inf
MaxThreshold = 220
MinArea = 25
MinCircularity = 0.8
MinConvexity = 0.95
MinDistance = 10
MinInertiaRatio = 0.1
MinRepeatability = 2
MinThreshold = 50
ThresholdStep = 10
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = BRISK
Type = Feature2D
Features = (Detector, Extractor)
Description = "The OpenCV BRISK Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/de/dbf/classcv_1_1BRISK.html"
CreatedUsing = brisk
Aliases = (brisk, detector.brisk, extractor.brisk, feature2d.brisk)
Group = Parameters
NOctaves = 3
PatternScale = 1.0
Threshold = 30
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = FAST
Type = Feature2D
Features = Detector
Description = "The OpenCV FAST Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/df/d74/classcv_1_1FASTFeature-
Detector.html"
CreatedUsing = fast
Aliases = (detector.fast, fast, fastx)
Group = Parameters
NonmaxSuppression = Yes
Threshold = 10
Type = TYPE_9_16
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = GFTT
Type = Feature2D
Features = Detector
Description = "The OpenCV GFTT Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/df/d21/classcv_1_1GFTTDetecto-
r.html"
CreatedUsing = gftt
Aliases = (detector.gftt, gftt)
Group = Parameters
BlockSize = 3
HarrisDetector = No
K = 0.04
MaxFeatures = 1000
MinDistance = 1.0
QualityLevel = 0.01
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = KAZE
Type = Feature2D
Features = (Detector, Extractor)
Description = "The OpenCV KAZE Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/d3/d61/classcv_1_1KAZE.html"
CreatedUsing = kaze
Aliases = (detector.kaze, extractor.kaze, feature2d.kaze, kaze)
Group = Parameters
Diffusivity = DIFF_PM_G2
Extended = No
NOctaveLayers = 4
NOctaves = 4
Threshold = 0.0010000000474975
Upright = No
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = MSD
Type = Feature2D
Features = Detector
Description = "The OpenCV MSD Feature2D detector/extractor algorithm. See
the documentation at
http://docs.opencv.org/3.1.0/d6/d36/classcv_1_1xfeatures2d-
_1_1MSD.html"
CreatedUsing = msd
Aliases = (detector.msd, msd)
Group = Parameters
ComputeOrientation = false
KNN = 4
NMSRadius = 5
NMSScaleRadius = 0
NScales = -1
PatchRadius = 3
ScaleFactor = 1.25
SearchAreaRadius = 5
THSaliency = 250.0
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = MSER
Type = Feature2D
Features = Detector
Description = "The OpenCV MSER Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/d3/d28/classcv_1_1MSER.html"
CreatedUsing = mser
Aliases = (detector.mser, mser)
Group = Parameters
AreaThreshold = 1.01
Delta = 5
EdgeBlurSize = 5
MaxArea = 14400
MaxEvolution = 200
MaxVariation = 0.25
MinArea = 60
MinDiversity = 0.2
MinMargin = 0.003
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = ORB
Type = Feature2D
Features = (Detector, Extractor)
Description = "The OpenCV ORB Feature2D detector/extractor algorithm. See
the documentation at
http://docs.opencv.org/3.1.0/db/d95/classcv_1_1ORB.html"
CreatedUsing = orb
Aliases = (detector.orb, extractor.orb, feature2d.orb, orb)
Group = Parameters
edgeThreshold = 31
fastThreshold = 20
firstLevel = 0
nfeatures = 500
nlevels = 8
patchSize = 31
scaleFactor = 1.2000000476837
scoreType = HARRIS_SCORE
WTA_K = 2
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = SIFT
Type = Feature2D
Features = (Detector, Extractor)
Description = "The OpenCV SIFT Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/d5/d3c/classcv_1_1xfeatures2d-
_1_1SIFT.html"
CreatedUsing = sift
Aliases = (detector.sift, extractor.sift, feature2d.sift, sift)
Group = Parameters
constrastThreshold = 0.04
edgeThreshold = 10
nfeatures = 0
nOctaveLayers = 3
sigma = 1.6
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = Star
Type = Feature2D
Features = Detector
Description = "The OpenCV Star Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/d6/d36/classcv_1_1xfeatures2d-
_1_1Star.html"
CreatedUsing = star
Aliases = (detector.star, star)
Group = Parameters
LineThresholdBinarized = 8
LineThresholdProjected = 10
MaxSize = 45
ResponseThreshold = 30
SuppressNonmaxSize = 5
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = SURF
Type = Feature2D
Features = (Detector, Extractor)
Description = "The OpenCV SURF Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/d5/df7/classcv_1_1xfeatures2d-
_1_1SURF.html"
CreatedUsing = surf
Aliases = (detector.surf, extractor.surf, feature2d.surf, surf)
Group = Parameters
Extended = No
HessianThreshold = 100.0
NOctaveLayers = 3
NOctaves = 4
Upright = No
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = Brief
Type = Feature2D
Features = Extractor
Description = "The OpenCV simple blob detection algorithm. See the
documentation at
http://docs.opencv.org/3.1.0/d0/d7a/classcv_1_1SimpleBlobD-
etector.html"
CreatedUsing = brief
Aliases = (brief, extractor.brief)
Group = Parameters
Bytes = 32
UseOrientation = true
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = DAISY
Type = Feature2D
Features = Extractor
Description = "The OpenCV DAISY Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/d9/d37/classcv_1_1xfeatures2d-
_1_1DAISY.html"
CreatedUsing = daisy
Aliases = (daisy, extractor.daisy)
Group = Parameters
H = "1,0,0,0,1,0,0,0,1"
interpolation = true
norm = NRM_NONE
q_hist = 8
q_radius = 3
q_theta = 8
radius = 15
use_orientation = false
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = FREAK
Type = Feature2D
Features = Extractor
Description = "The OpenCV FREAK Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/df/db4/classcv_1_1xfeatures2d-
_1_1FREAK.html"
CreatedUsing = freak
Aliases = (extractor.freak, freak)
Group = Parameters
NOctaves = 4
OrientationNormalized = true
PatternScale = 22.0
ScaleNormalized = true
SelectedPairs = Null
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = LATCH
Type = Feature2D
Features = Extractor
Description = "The OpenCV LATCH Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/d6/d36/classcv_1_1xfeatures2d-
_1_1LATCH.html"
CreatedUsing = latch
Aliases = (extractor.latch, latch)
Group = Parameters
Bytes = 32
HalfSSDSize = 3
RotationInvariance = true
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = LUCID
Type = Feature2D
Features = Extractor
Description = "The OpenCV LUCID Feature2D detector/extractor algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/d6/d36/classcv_1_1xfeatures2d-
_1_1LUCID.html"
CreatedUsing = lucid
Aliases = (extractor.lucid, lucid)
Group = Parameters
BlurKernel = 1
LucidKernel = 1
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = BFMatcher
Type = DecriptorMatcher
Features = Matcher
Description = "The OpenCV BFMatcher DescriptorMatcher matcher algorithm.
See the documentation at
http://docs.opencv.org/3.1.0/d3/da1/classcv_1_1BFMatcher.h-
tml"
CreatedUsing = bfmatcher
Aliases = (bfmatcher, matcher.bfmatcher)
Group = Parameters
CrossCheck = No
NormType = NORM_L2
End_Group
End_Object
Object = Algorithm
CVVersion = 3.1.0
Name = FlannBasedMatcher
Type = DecriptorMatcher
Features = Matcher
Description = "The OpenCV FlannBasedMatcher DescriptorMatcher matcher
algorithm. See the documentation at
http://docs.opencv.org/3.1.0/dc/de2/classcv_1_1FlannBasedM-
atcher.html"
CreatedUsing = flannbasedmatcher
Aliases = (flannbasedmatcher, matcher.flannbasedmatcher)
Group = Parameters
Checks = 32
Epsilon = 0.0
Sorted = Yes
End_Group
End_Object
End_Object
End
|